NovaMLX
The blazing fast pure-Swift LLM/VLM server for Apple Silicon.
No Python. Native performance. Cloud via tknet.ai.
Built for Engineers, by Engineers
Native macOS menu bar app. Full-featured chat UI. Admin dashboard. Everything you need, nothing you don't.
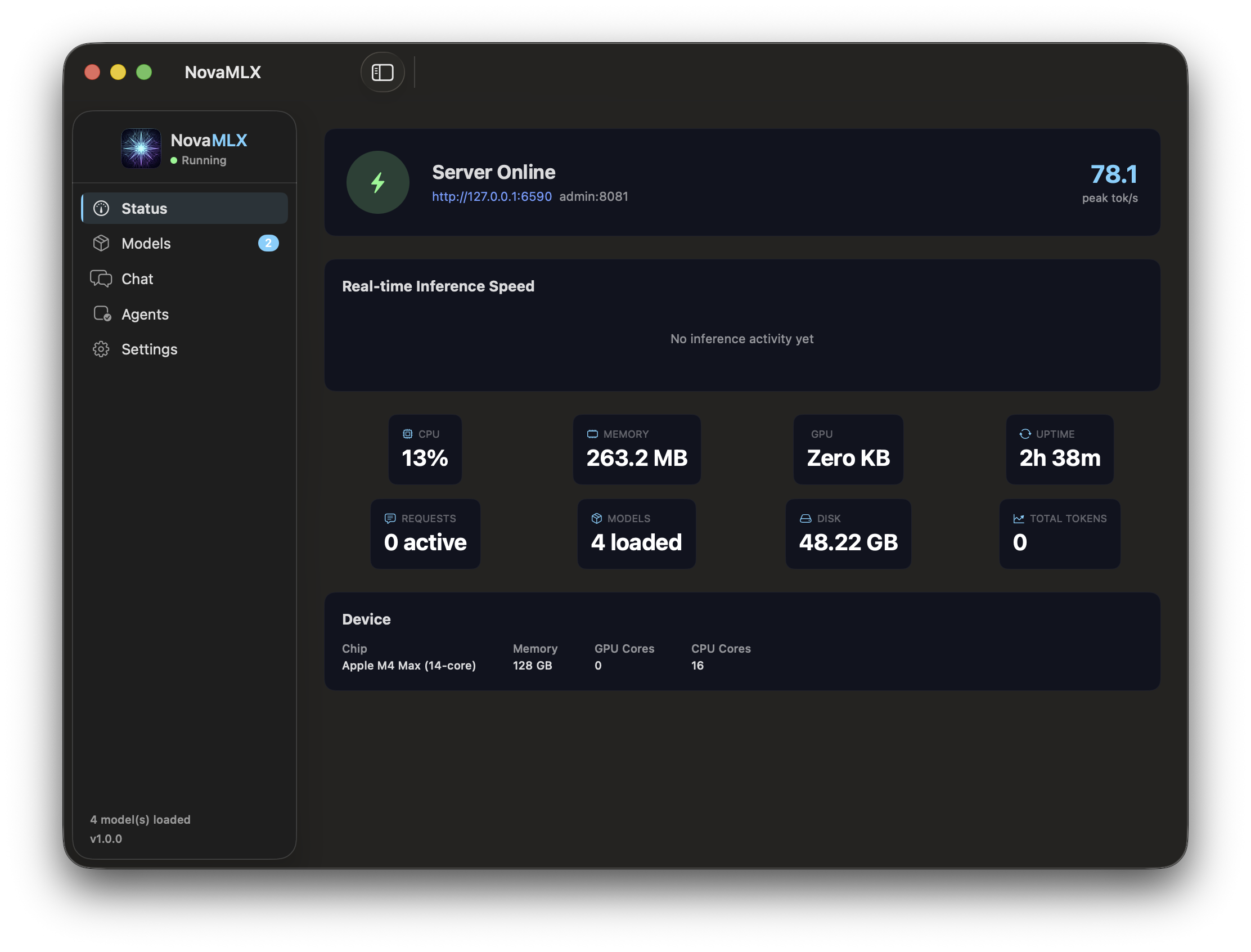
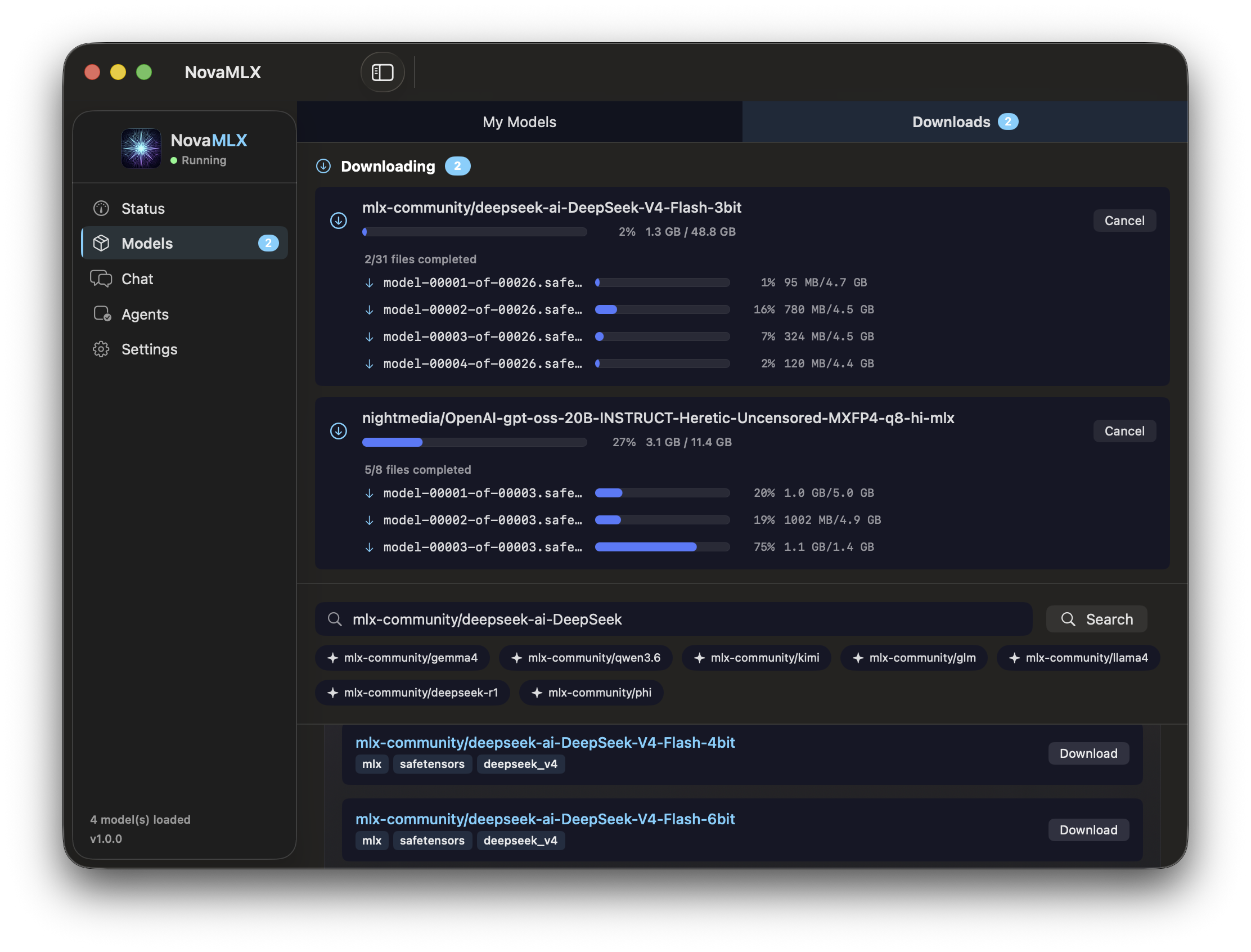
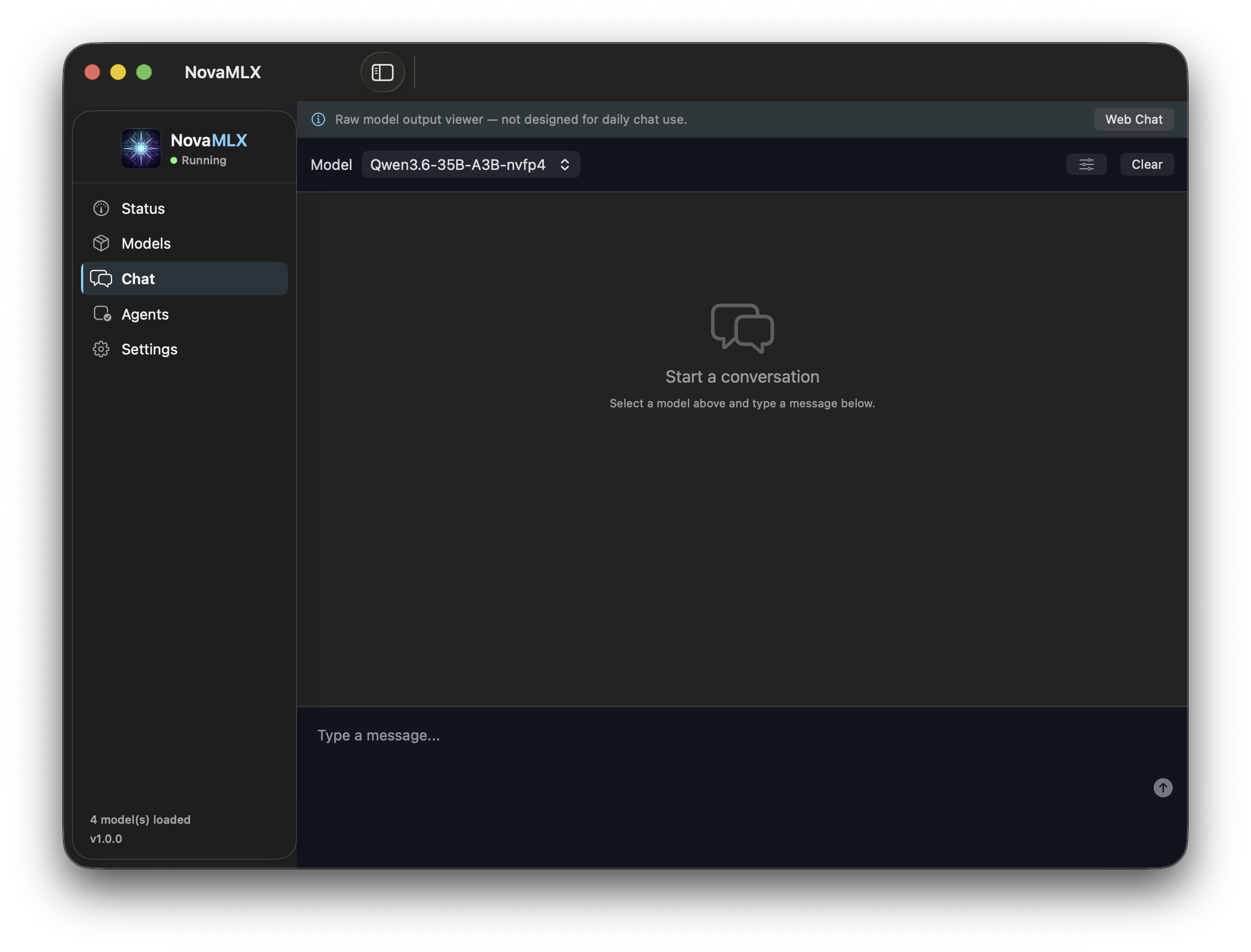
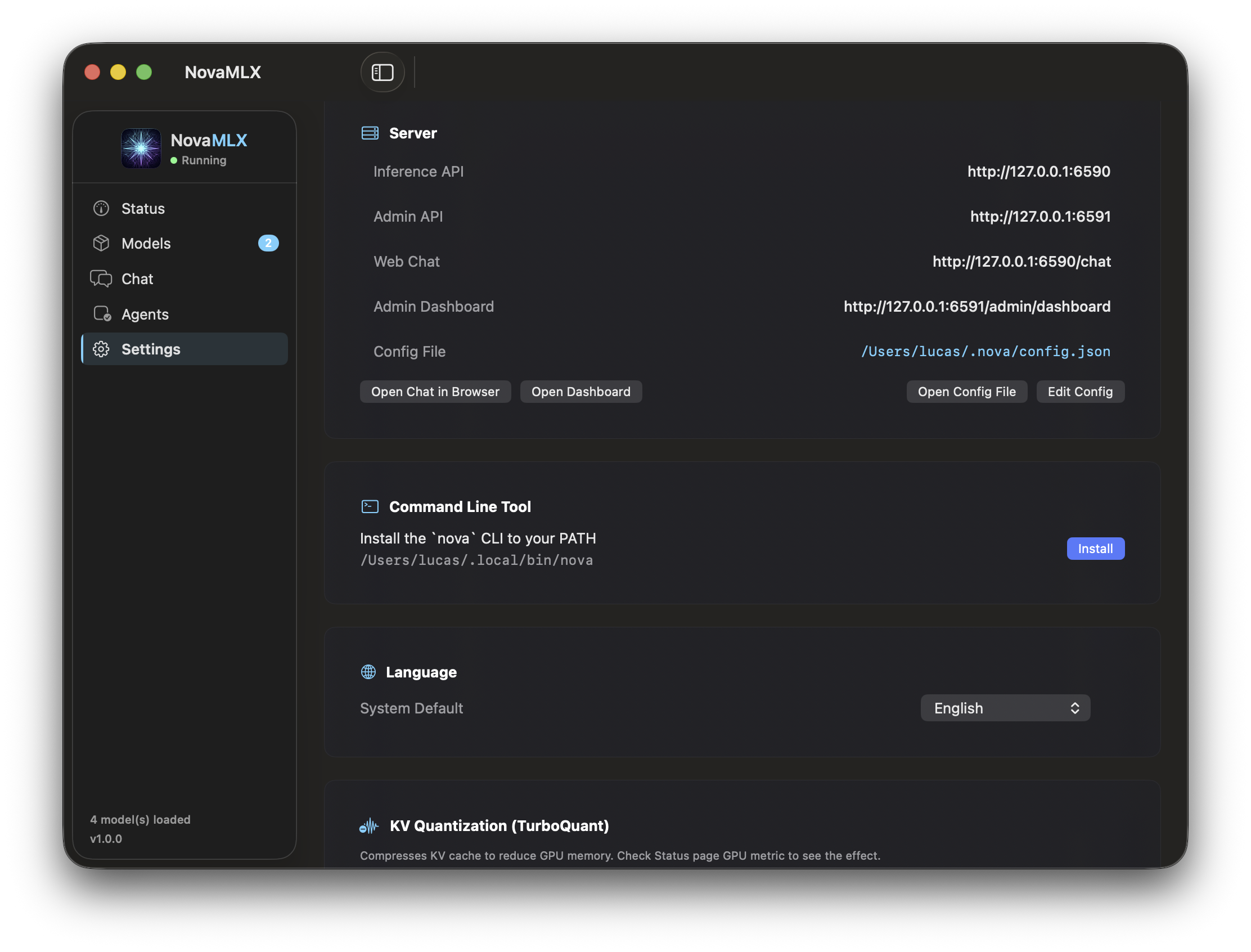
Why So Fast?
Every layer of the stack is optimized for Apple Silicon — from GPU kernels to memory management.
Pure Swift + Metal
Swift 6.0No Python runtime, no GIL, no FFI bridge. Direct Metal GPU access via MLX — compiled to native code, zero overhead.
Fused Batch Decode
Batch ×8Multiple sequences share a single GPU forward pass per decode step. Up to 8 concurrent requests with priority-aware scheduling.
Prefix Cache
100GB SSDBlock-level paged KV cache with SHA-1 chain hashing. Cross-session reuse saves ~90% prefill on repeated prompts.
TurboQuant
Up to 8×Per-model KV cache quantization: 2/3/4/6/8-bit with auto-recommendation. 4-bit gives 4× memory savings with minimal quality loss.
Speculative Decoding
Free speedupN-gram pattern matching drafts up to 5 tokens ahead — zero secondary model needed. Verified in a single forward pass.
Compiled Sampling
JIT-compiledTemperature, top-p, top-k, min-p are JIT-compiled via MLX compile() — not interpreted, not Python-implemented.
TurboQuant KV Compression
Configurable per-model KV cache quantization — auto-recommended based on model size and available memory.
| Quantization | Compression | Use Case |
|---|---|---|
| 2-bit | 8.0× | Extreme memory pressure |
| 3-bit | 5.33× | High memory pressure |
| 4-bit | 4.0× | Balanced (recommended) |
| 6-bit | 2.67× | Quality-sensitive |
| 8-bit | 2.0× | Minimal quality loss |
Why NovaMLX?
Run 50+ model families — Llama, Qwen, Gemma, DeepSeek, Mistral — natively on your Mac.
Blazing Fast
Pure Swift on Apple Silicon. No Python overhead. Native Metal GPU acceleration.
50+ Model Families
Llama 3, Qwen 2/2.5/3, Gemma 2/3, Phi 4, Mistral, DeepSeek, and more.
OpenAI & Anthropic API
Drop-in compatible. Point any tool at localhost and it just works.
Vision (VLM)
Send images with messages. Supports Qwen2-VL, Gemma3, LLaVA, and others.
Structured Output
Force JSON, regex, or GBNF grammar. Schema validation built in.
Tool Calling
Automatic tool detection across 7 format families. No fine-tuning needed.
Get Started in 30 Seconds
Download. Install. Download a model. Start chatting.
Download NovaMLX
Grab the latest .dmg from GitHub Releases.
Install
Open the .dmg → Drag NovaMLX to Applications.
Download a model
Launch NovaMLX → Browse models → Pick one and download.
Activate & start
Select your model → Start chatting with local inference.
Once your model is running, connect it to your favorite tools — OpenClaw, Cherry Studio, Claude Code, Open Code, and more.
See details →Missing a Feature? We Build It.
NovaMLX isn't just open source — it's developed on demand. Need a new model architecture, a custom quantization strategy, or an integration with your workflow? Open an issue, and we ship it.
You Request
Describe the feature or integration you need in a GitHub issue.
We Build
We evaluate, prioritize, and implement — often within days.
You Ship
New release, new capability. Update NovaMLX and it's there.